Machine Learning 14: Classification Εδαφών με Gaussian Discriminant Analysis (GDA)
Gaussian Discriminant Analysis (GDA)
Το Gaussian Discriminant Analysis (GDA) είναι ένας αλγόριθμος ταξινόμησης που βασίζεται στις πιθανότητες. Ανήκει στην κατηγορία των generative models, δηλαδή προσπαθεί να περιγράψει πώς δημιουργούνται τα δεδομένα κάθε κατηγορίας.
Η βασική ιδέα
Το GDA υποθέτει ότι τα δεδομένα κάθε κατηγορίας ακολουθούν μια κανονική (Gaussian) κατανομή.
Για παράδειγμα, αν μετράμε το pH του εδάφους:
- Όξινο έδαφος → τιμές γύρω στο 5
- Ουδέτερο έδαφος → τιμές γύρω στο 7
- Αλκαλικό έδαφος → τιμές γύρω στο 9
Οι τιμές αυτές δεν είναι σταθερές, αλλά σχηματίζουν gaussian κατανομές. Κάθε κατηγορία έχει τη δική της κατανομή.
Τι μαθαίνει το μοντέλο
Για κάθε κατηγορία, το GDA υπολογίζει:
- Μέσο όρο (μ) – πού βρίσκονται τα δεδομένα
- Διασπορά (σ²) – πόσο απλώνονται
Με αυτές τις πληροφορίες μπορεί να εκτιμήσει πόσο πιθανό είναι ένα νέο δείγμα να ανήκει σε κάθε κατηγορία.
Η Gaussian κατανομή
f(x) = (1 / √(2πσ²)) * e^(-(x - μ)² / (2σ²))
Η παραπάνω συνάρτηση περιγράφει την κανονική κατανομή.
Πώς γίνεται η ταξινόμηση
- Δίνουμε μια νέα τιμή (π.χ. pH = 6.5)
- Το μοντέλο υπολογίζει το likelihood P(x | class) για κάθε κατηγορία
- Πολλαπλασιάζει με το prior P(class)
- Επιλέγεται η κατηγορία με τη μεγαλύτερη τελική πιθανότητα
GDA vs Logistic Regression
| GDA | Logistic Regression |
|---|---|
| Μοντελοποιεί τα δεδομένα | Μοντελοποιεί το όριο απόφασης |
| Υποθέτει Gaussian κατανομές | Δεν κάνει τέτοια υπόθεση |
| Generative model | Discriminative model |
Το Dataset μας
Για να κατανοήσουμε πώς λειτουργεί το Gaussian Discriminant Analysis (GDA), θα δημιουργήσουμε ένα απλό dataset από τον χώρο της γεωλογίας.
Θα χρησιμοποιήσουμε μία βασική παράμετρο: το pH του εδάφους.
Κατηγορίες εδαφών
| Κατηγορία | Περιγραφή | Τυπικές τιμές pH |
|---|---|---|
| Όξινο (Acidic) | Έδαφος με χαμηλό pH | ≈ 4.5 – 6 |
| Ουδέτερο (Neutral) | Ισορροπημένο pH | ≈ 6.5 – 7.5 |
| Αλκαλικό (Alkaline) | Έδαφος με υψηλό pH | ≈ 8 – 9.5 |
Πώς δημιουργήσαμε τα δεδομένα
Αντί να βάλουμε τυχαίες τιμές, δημιουργήσαμε δεδομένα που ακολουθούν Gaussian κατανομές.
- Κάθε κατηγορία έχει έναν μέσο όρο (μ)
- Υπάρχει διασπορά (σ²), ώστε τα δεδομένα να μην είναι όλα ίδια
Οπτικοποίηση δεδομένων
Στο παρακάτω γράφημα βλέπουμε τα δεδομένα μας:
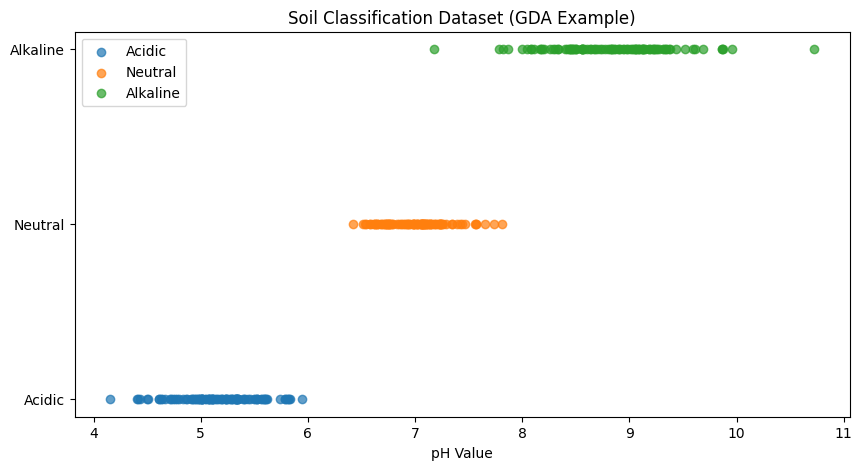
- Κάθε σημείο είναι ένα δείγμα εδάφους
- Ο οριζόντιος άξονας δείχνει το pH
- Τα χρώματα αντιστοιχούν στις κατηγορίες
Παρατήρησε ότι τα δεδομένα σχηματίζουν "ομάδες" γύρω από συγκεκριμένες τιμές. Αυτό ακριβώς εκμεταλλεύεται το GDA.
Εκπαίδευση GDA – Βήμα 1: Υπολογισμός Μέσου Όρου
Το πρώτο βήμα στο Gaussian Discriminant Analysis είναι να υπολογίσουμε τον μέσο όρο (mean) για κάθε κατηγορία.
Ο μέσος όρος μας δείχνει πού "συγκεντρώνονται" τα δεδομένα κάθε κατηγορίας.
Το GDA υποθέτει ότι κάθε κατηγορία ακολουθεί μια Gaussian κατανομή. Ο μέσος όρος είναι το κέντρο αυτής της κατανομής.
Μαθηματικός ορισμός
μ = (x₁ + x₂ + ... + xₙ) / n
Στο Παράδειγμα:
- Όξινο έδαφος → μέσο pH = 5.158
- Ουδέτερο έδαφος → μέσο pH =7.007
- Αλκαλικό έδαφος → μέσο pH =8.832
Εκπαίδευση GDA – Βήμα 2: Υπολογισμός Διασποράς (Variance)
Η διασπορά μας δείχνει πόσο "απλωμένα" είναι τα δεδομένα γύρω από τον μέσο όρο.
Μαθηματικός ορισμός
σ² = (1/n) * Σ (xᵢ - μ)²
Το GDA χρησιμοποιεί τη διασπορά για να κατασκευάσει την Gaussian κατανομή κάθε κατηγορίας.
- Ο μέσος όρος καθορίζει το κέντρο
- Η διασπορά καθορίζει το "πλάτος" της καμπύλης
Χωρίς τη διασπορά, δεν μπορούμε να υπολογίσουμε σωστά τις πιθανότητες.
Στο παράδειγμά:
Για κάθε κατηγορία εδάφους υπολογίζουμε:
- Variance για Όξινο έδαφος: 0.131
- Variance για Ουδέτερο έδαφος: 0.081
- Variance για Αλκαλικό έδαφος: 0.291
Εκπαίδευση GDA – Βήμα 3: Υπολογισμός Πιθανοτήτων & Πρόβλεψη
Αφού έχουμε υπολογίσει τον μέσο όρο (μ) και τη διασπορά (σ²) για κάθε κατηγορία, μπορούμε πλέον να εκτιμήσουμε σε ποια κατηγορία ανήκει ένα νέο δείγμα.
Η βασική ιδέα
Για μια νέα τιμή pH (π.χ. x = 6.5), το GDA κάνει τα εξής:
- Υπολογίζει πόσο πιθανό είναι το x για κάθε κατηγορία (likelihood)
- Λαμβάνει υπόψη πόσο συχνή είναι κάθε κατηγορία (prior)
- Συνδυάζει τα δύο για να πάρει την τελική απόφαση
Likelihood (Gaussian)
Υπολογίζουμε:
- P(x | Acidic)
- P(x | Neutral)
- P(x | Alkaline)
f(x) = (1 / √(2πσ²)) * e^(-(x - μ)² / (2σ²))
Prior
Κάθε κατηγορία έχει μια αρχική πιθανότητα:
- P(Acidic)
- P(Neutral)
- P(Alkaline)
Υλοποίηση Python
Mean pH values: Acidic: 5.158 Neutral: 7.007 Alkaline: 8.832 Variance values: Acidic: 0.131 Neutral: 0.081 Alkaline: 0.291 Likelihoods P(x | class): Acidic: 0.00113 Neutral: 0.28748 Alkaline: 0.00006
Εκπαίδευση GDA – Βήμα 4: Decision Boundary & Οπτικοποίηση
Αφού έχουμε εκπαιδεύσει το μοντέλο και μπορούμε να υπολογίζουμε πιθανότητες, μπορούμε τώρα να δούμε πώς το GDA χωρίζει τις κατηγορίες.
Τι είναι το Decision Boundary;
Το decision boundary είναι το σημείο όπου δύο κατηγορίες έχουν την ίδια πιθανότητα.
Για παράδειγμα:
- Το όριο μεταξύ Acidic και Neutral είναι εκεί όπου:
P(x | Acidic) = P(x | Neutral)
Σε αυτό το σημείο, το μοντέλο "δεν είναι σίγουρο" και αλλάζει κατηγορία.
Οπτικοποίηση Gaussian Καμπυλών
Μπορούμε να σχεδιάσουμε τις κατανομές κάθε κατηγορίας για να δούμε πώς επικαλύπτονται.
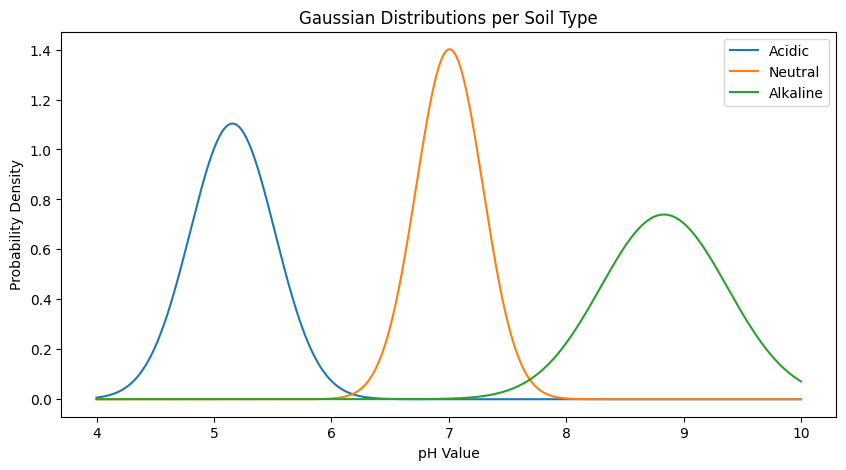
- Κάθε κατηγορία σχηματίζει μια καμπύλη
- Οι καμπύλες επικαλύπτονται
- Τα σημεία τομής είναι τα decision boundaries
Εκπαίδευση GDA – Βήμα 5: Bayesian Gaussian Discriminant Analysis
Μέχρι τώρα υπολογίζαμε μόνο την πιθανότητα των δεδομένων γνωρίζοντας την κατηγορία:
P(x | class)
Όμως το πραγματικό ζητούμενο είναι:
P(class | x)
Δηλαδή: ποια είναι η πιθανότητα ένα δείγμα να ανήκει σε μια κατηγορία.
Ο Κανόνας του Bayes
Για να το υπολογίσουμε, χρησιμοποιούμε τον κανόνα του Bayes:
P(class | x) = (P(x | class) * P(class)) / P(x)
Τι είναι το P(class);
Είναι η αρχική πιθανότητα (prior) μιας κατηγορίας.
- Αν έχουμε πολλά Neutral δείγματα → P(Neutral) είναι μεγαλύτερο
- Αν έχουμε λίγα Acidic → P(Acidic) είναι μικρότερο
Πώς γίνεται η πρόβλεψη
- Υπολογίζουμε P(x | class) (Gaussian)
- Πολλαπλασιάζουμε με P(class)
- Διαλέγουμε τη μεγαλύτερη τιμή
Παράδειγμα
- P(x | Neutral) = 0.5
- P(Neutral) = 0.6
Τελική τιμή:
0.5 * 0.6 = 0.3
Πώς γίνεται η ταξινόμηση (classification)
- Παίρνουμε μια νέα τιμή (π.χ. pH = 6.5)
- Υπολογίζουμε P(x | class) με τη Gaussian
- Μετατρέπουμε σε P(class | x) με Bayes
- Επιλέγουμε τη μεγαλύτερη τιμή
Κώδικας
# Gaussian Discriminant Analysis - Classification Example
import math
# Mean values
means = {
"Acidic": 5.158,
"Neutral": 7.007,
"Alkaline": 8.832
}
# Variance values
variances = {
"Acidic": 0.131,
"Neutral": 0.081,
"Alkaline": 0.291
}
# Prior probabilities (π.χ.για απλοποίηση ολες οι κατηγορίες εχουν ίδια πιθανότητα)
priors = {
"Acidic": 1/3,
"Neutral": 1/3,
"Alkaline": 1/3
}
# Gaussian likelihood function
def gaussian_likelihood(x, mean, var):
return (1 / math.sqrt(2 * math.pi * var)) * math.exp(-(x - mean)**2 / (2 * var))
# Κύρια συνάρτηση ταξινόμησης
def classify_ph(x):
posteriors = {}
for cls in means:
likelihood = gaussian_likelihood(x, means[cls], variances[cls])
posterior = likelihood * priors[cls] # P(class|x) ~ P(x|class) * P(class)
posteriors[cls] = posterior
# Επιλογή κατηγορίας με τη μεγαλύτερη πιθανότητα
predicted_class = max(posteriors, key=posteriors.get)
return predicted_class, posteriors
# Ζητάμε νέα τιμή pH
new_ph = float(input("Δώσε την τιμή pH του εδάφους: "))
predicted_class, posteriors = classify_ph(new_ph)
print(f"\nΗ κατηγορία του εδάφους είναι: {predicted_class}")
print("Πιθανότητες ανά κατηγορία:")
for cls, prob in posteriors.items():
print(f"{cls}: {prob:.5f}")
Γιατί βάλαμε ίσα priors;
Στο παράδειγμα χρησιμοποιήσαμε:
priors = {
"Acidic": 1/3,
"Neutral": 1/3,
"Alkaline": 1/3
}Αυτό σημαίνει ότι:
- Όλες οι κατηγορίες θεωρούνται εξίσου πιθανές
- Δεν έχουμε πληροφορία για πραγματική κατανομή δεδομένων
- Το μοντέλο βασίζεται κυρίως στο likelihood
Gaussian Likelihood
def gaussian_likelihood(x, mean, var):
return (1 / math.sqrt(2 * math.pi * var)) * \
math.exp(-(x - mean)**2 / (2 * var))Αυτή η συνάρτηση υπολογίζει την πιθανότητα μιας τιμής pH να ανήκει σε μια κατηγορία.
Υπολογισμός Posterior
posterior = likelihood * priorΓια κάθε κατηγορία:
- Υπολογίζουμε το likelihood
- Το πολλαπλασιάζουμε με το prior
- Διαλέγουμε το μέγιστο
Πλήρης Συνάρτηση Ταξινόμησης
def classify_ph(x):
posteriors = {}
for cls in means:
likelihood = gaussian_likelihood(x, means[cls], variances[cls])
posterior = likelihood * priors[cls]
posteriors[cls] = posterior
predicted_class = max(posteriors, key=posteriors.get)
return predicted_class, posteriorsΠότε αλλάζουν τα Priors;
Αν έχουμε πραγματικά δεδομένα:
priors = {
"Acidic": 0.5,
"Neutral": 0.3,
"Alkaline": 0.2
}Τότε το μοντέλο λαμβάνει υπόψη ότι κάποιες κατηγορίες είναι πιο συχνές.
Βιβλιογραφία
Stanford Online. Stanford CS229: Machine Learning - Perceptron & Generalized Linear Model | Lecture 4 (Autumn 2018) [Video]. YouTube. https://youtu.be/iZTeva0WSTQ?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU