Machine Learning 15: GDA σε 2D dataset
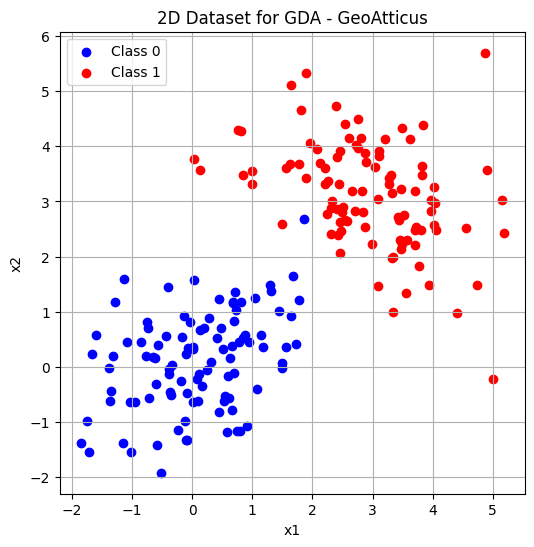
Βήμα 1: Υπολογίζουμε τα Means (μ₀, μ₁)
Χωρίζουμε το dataset σε classes και υπολογίζουμε το mean vector για κάθε class:
μ₀ = average of all points where y = 0
μ₁ = average of all points where y = 1
στην προκειμένη περίπτωση έχουμε:
mu0: [0.08307042 0.11709274]
mu1: [2.92233021 3.12912507]
Βήμα 2: Covariance Matrix (Σ)
Το Σ περιγράφει πώς είναι απλωμένα τα δεδομένα γύρω από το mean (μ) για κάθε κλάση.
Δικό μας παράδειγμα
Σ₀:
[[0.82, 0.30],
[0.30, 0.77]]
Σ₁:
[[1.08, -0.39],
[-0.39, 0.93]]
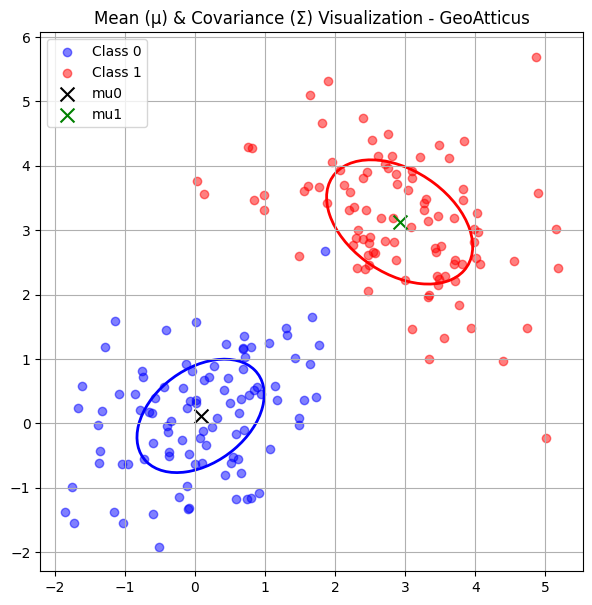
Κάθε αριθμός μέσα στο Σ μας δίνει πληροφορία για το πώς απλώνονται τα δεδομένα. Τα δύο στοιχεία στη διαγώνιο (πάνω αριστερά και κάτω δεξιά) δείχνουν πόσο "απλωμένα" είναι τα σημεία στον άξονα x και στον άξονα y αντίστοιχα. Όσο μεγαλύτερος ο αριθμός, τόσο πιο μεγάλη η διασπορά. Τα υπόλοιπα στοιχεία (εκτός διαγωνίου) δείχνουν τη σχέση μεταξύ των δύο αξόνων: αν είναι θετικά, τότε όταν αυξάνεται το x τείνει να αυξάνεται και το y, ενώ αν είναι αρνητικά, όταν αυξάνεται το x το y τείνει να μειώνεται. Με απλά λόγια, το Σ δεν μας λέει μόνο πόσο "απλωμένα" είναι τα δεδομένα, αλλά και προς ποια κατεύθυνση απλώνονται.
Βήμα 3: Prior πιθανότητα (φ)
Το φ (phi) εκφράζει την πιθανότητα ένα τυχαίο σημείο να ανήκει στην κλάση 1.
φ = P(y = 1)
Υπολογίζεται απλά ως το ποσοστό των δεδομένων που ανήκουν στην κλάση 1.
Στο dataset μας:
φ = 0.5
Οι δύο κλάσεις έχουν ίδιο αριθμό σημείων, άρα το μοντέλο δεν "προτιμά" κάποια κλάση από πριν.
Βήμα 4: Πόσο πιθανό είναι ένα σημείο (Likelihood)
Τώρα θέλουμε να δούμε σε ποια κλάση ανήκει ένα νέο σημείο x.
Για κάθε κλάση υπολογίζουμε πόσο πιθανό είναι το x να προέρχεται από αυτή:
- P(x | y = 0)
- P(x | y = 1)
Η πιθανότητα αυτή υπολογίζεται με την κανονική κατανομή (Gaussian):
Όπου:
- μ = mean της κλάσης
- Σ = covariance matrix
- Σ⁻¹ = inverse του covariance
- |Σ| = determinant του covariance
Πώς το υπολογίζουμε βήμα-βήμα
- Υπολογίζουμε τη διαφορά (x - μ)
- Υπολογίζουμε το (x - μ)T Σ⁻¹ (x - μ)
- Βάζουμε το αποτέλεσμα μέσα στην exp()
- Πολλαπλασιάζουμε με τον συντελεστή κανονικοποίησης
Στο τέλος παίρνουμε δύο τιμές:
- P(x | y = 0)
- P(x | y = 1)
και τις χρησιμοποιούμε στο επόμενο βήμα για να αποφασίσουμε την κλάση.
Βήμα 5: Posterior πιθανότητα (Bayes Rule)
Τώρα θέλουμε να υπολογίσουμε την πιθανότητα μια κλάση να ισχύει δεδομένου ενός σημείου x:
P(y | x)
Χρησιμοποιούμε τον κανόνα του Bayes:
Δεν χρειάζεται να υπολογίσουμε το P(x), γιατί είναι ίδιο για όλες τις κλάσεις. Άρα συγκρίνουμε μόνο τα:
- P(x | y = 0) * (1 - φ)
- P(x | y = 1) * φ
Απόφαση:
- Αν P(x | y = 1) * φ > P(x | y = 0) * (1 - φ) → το σημείο ανήκει στην κλάση 1
- Αλλιώς → ανήκει στην κλάση 0
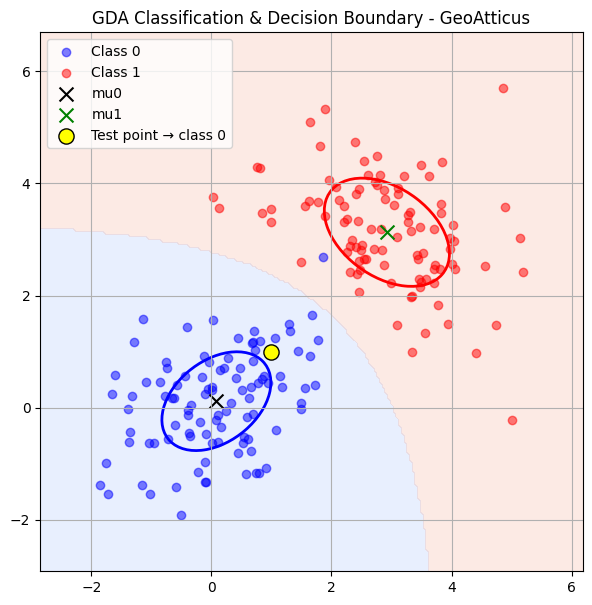
Βήμα 6: Decision Boundary
Το decision boundary είναι η γραμμή (ή καμπύλη) που χωρίζει τις δύο κλάσεις.
Βρίσκεται εκεί όπου:
Ανάλογα με τα covariance matrices:
- Αν Σ₀ = Σ₁ → το boundary είναι ευθεία (linear)
- Αν Σ₀ ≠ Σ₁ → το boundary είναι καμπύλη (quadratic)
Στο παράδειγμά μας, επειδή τα Σ₀ και Σ₁ είναι διαφορετικά, το σύνορο απόφασης θα είναι καμπύλη.
Συμπέρασμα
Το Gaussian Discriminant Analysis (GDA) βασίζεται στην υπόθεση ότι τα δεδομένα κάθε κλάσης ακολουθούν κανονική κατανομή.
- Υπολογίζουμε τα means (μ₀, μ₁)
- Υπολογίζουμε τα covariance matrices (Σ₀, Σ₁)
- Υπολογίζουμε την prior πιθανότητα (φ)
- Υπολογίζουμε likelihood για κάθε κλάση
- Επιλέγουμε την πιο πιθανή κλάση
Με αυτόν τον τρόπο μπορούμε να ταξινομήσουμε νέα σημεία στο dataset μας.
Ο Κώδικας
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
np.random.seed(42)
n = 100
# =========================
# Δημιουργία δεδομένων
# =========================
mean0 = [0, 0]
cov0 = [[1, 0.5], [0.5, 1]]
X0 = np.random.multivariate_normal(mean0, cov0, n)
mean1 = [3, 3]
cov1 = [[1, -0.3], [-0.3, 1]]
X1 = np.random.multivariate_normal(mean1, cov1, n)
X = np.vstack((X0, X1))
y = np.array([0]*n + [1]*n)
# =========================
# Υπολογισμός μ και Σ
# =========================
mu0 = X0.mean(axis=0)
mu1 = X1.mean(axis=0)
Sigma0 = np.cov(X0.T)
Sigma1 = np.cov(X1.T)
# =========================
# Gaussian PDF
# =========================
def gaussian_pdf(x, mu, Sigma):
n = len(mu)
det = np.linalg.det(Sigma)
inv = np.linalg.inv(Sigma)
norm_const = 1 / ((2 * np.pi) ** (n / 2) * np.sqrt(det))
diff = x - mu
return norm_const * np.exp(-0.5 * diff.T @ inv @ diff)
# =========================
# Classifier (GDA)
# =========================
phi = 0.5
def predict(x):
p0 = gaussian_pdf(x, mu0, Sigma0) * (1 - phi)
p1 = gaussian_pdf(x, mu1, Sigma1) * phi
return 1 if p1 > p0 else 0
# =========================
# Ellipse σχεδίαση
# =========================
def draw_ellipse(mean, cov, ax, color):
eigenvalues, eigenvectors = np.linalg.eigh(cov)
angle = np.degrees(np.arctan2(*eigenvectors[:,0][::-1]))
width, height = 2 * np.sqrt(eigenvalues)
ellipse = patches.Ellipse(mean, width, height, angle=angle,
edgecolor=color, facecolor='none', linewidth=2)
ax.add_patch(ellipse)
# =========================
# Grid για decision boundary
# =========================
x_min, x_max = X[:,0].min() - 1, X[:,0].max() + 1
y_min, y_max = X[:,1].min() - 1, X[:,1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200),
np.linspace(y_min, y_max, 200))
Z = np.zeros(xx.shape)
for i in range(xx.shape[0]):
for j in range(xx.shape[1]):
point = np.array([xx[i, j], yy[i, j]])
Z[i, j] = predict(point)
# =========================
# Plot
# =========================
fig, ax = plt.subplots(figsize=(7,7))
# Decision boundary (background)
ax.contourf(xx, yy, Z, alpha=0.2, levels=1, cmap='coolwarm')
# Δεδομένα
ax.scatter(X0[:,0], X0[:,1], color='blue', alpha=0.5, label='Class 0')
ax.scatter(X1[:,0], X1[:,1], color='red', alpha=0.5, label='Class 1')
# Means
ax.scatter(mu0[0], mu0[1], color='black', marker='x', s=100, label='mu0')
ax.scatter(mu1[0], mu1[1], color='green', marker='x', s=100, label='mu1')
# Ellipses
draw_ellipse(mu0, Sigma0, ax, 'blue')
draw_ellipse(mu1, Sigma1, ax, 'red')
# Test point
test_point = np.array([1, 1])
pred = predict(test_point)
ax.scatter(test_point[0], test_point[1],
color='yellow', edgecolor='black', s=120,
label=f'Test point → class {pred}')
# Labels
ax.set_title("GDA Classification & Decision Boundary")
ax.grid(True)
ax.legend()
plt.show()
Η συνάρτηση gaussian_pdf υπολογίζει την πιθανότητα ένα σημείο x να προέρχεται από μια κανονική κατανομή με mean μ και covariance Σ.
def gaussian_pdf(x, mu, Sigma):
n = len(mu)
det = np.linalg.det(Sigma)
inv = np.linalg.inv(Sigma)
norm_const = 1 / ((2 * np.pi) ** (n / 2) * np.sqrt(det))
diff = x - mu
return norm_const * np.exp(-0.5 * diff.T @ inv @ diff)
Αυτή η συνάρτηση υλοποιεί τον μαθηματικό τύπο της Gaussian κατανομής. Όσο πιο κοντά είναι το x στο μ, τόσο μεγαλύτερη τιμή επιστρέφει.
Η ταξινόμηση γίνεται εδώ:
def predict(x):
p0 = gaussian_pdf(x, mu0, Sigma0) * (1 - phi)
p1 = gaussian_pdf(x, mu1, Sigma1) * phi
return 1 if p1 > p0 else 0
Τι κάνει βήμα-βήμα:
- Υπολογίζει την πιθανότητα το x να ανήκει στην κλάση 0 → p0
- Υπολογίζει την πιθανότητα το x να ανήκει στην κλάση 1 → p1
- Συγκρίνει τις δύο τιμές
- Επιστρέφει την κλάση με τη μεγαλύτερη πιθανότητα
Βιβλιογραφία
Stanford Online. Stanford CS229: Machine Learning - Perceptron & Generalized Linear Model | Lecture 4 (Autumn 2018) [Video]. YouTube. https://youtu.be/iZTeva0WSTQ?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU