Machine Learning 16: Support Vector Machine
Ξεκινάμε με ένα απλό dataset 20 σημείων.
Η βασική ιδέα του SVM είναι η εξής:
- Βρίσκουμε μια γραμμή που χωρίζει τις κατηγορίες
- Μεγιστοποιούμε την απόσταση (margin) από τα κοντινότερα σημεία
- Αγνοούμε τα σημεία που είναι μακριά από το όριο
Αυτό κάνει το SVM ιδιαίτερα ισχυρό, γιατί οδηγεί σε μοντέλα που γενικεύουν καλύτερα σε νέα δεδομένα.
Πρώτο βήμα: Πολλές πιθανές γραμμές διαχωρισμού
Αν παρατηρήσουμε το dataset, μπορούμε να φανταστούμε πολλές διαφορετικές γραμμές που διαχωρίζουν τις δύο κατηγορίες.
Δηλαδή, δεν υπάρχει μία μόνο λύση στο πρόβλημα της ταξινόμησης. Μπορούμε να σχεδιάσουμε πολλές γραμμές που χωρίζουν σωστά τα δεδομένα.
Το Support Vector Machine θα απαντήσει ακριβώς σε αυτό το ερώτημα:
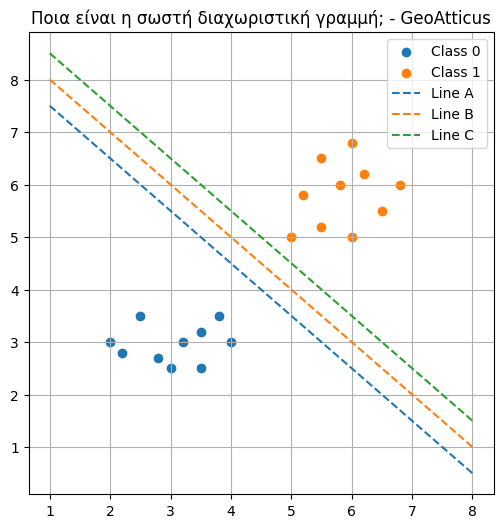
Ποια γραμμή είναι η καλύτερη;
Από τις προηγούμενες γραμμές, όλες διαχωρίζουν σωστά τα δεδομένα. Όμως δεν είναι όλες εξίσου καλές.
Κάποιες γραμμές περνούν πολύ κοντά από σημεία των κατηγοριών, ενώ άλλες αφήνουν μεγαλύτερη απόσταση.
Η γραμμή ονομάζεται hyperplane (Ηο) και η απόσταση ονομάζεται margin ή street.
Στόχος του SVM είναι να μεγιστοποιήσει αυτό το margin, ώστε το μοντέλο να είναι πιο σταθερό και να γενικεύει καλύτερα σε νέα δεδομένα.
Η εξίσωση της ευθείας
Η ευθεία (ή γενικά το hyperplaneσε περισσότερες διαστάσεις) γράφεται ως:
όπου:
- w: διάνυσμα βαρών
- x: διάνυσμα σημείων
- b: bias
Περιορισμοί ταξινόμησης
Θέλουμε τα σημεία να ταξινομούνται σωστά:
όπου:
- yᵢ = +1 ή -1 (label), ανάλογα αν είναι στο μέρος του plane H1 ή plane H2
- xᵢ = δεδομένα
Το Margin
Το margin δίνεται από:
Άρα:
Το Optimization Problem
Το SVM γίνεται τελικά ένα πρόβλημα βελτιστοποίησης:
Αυτό είναι το βασικό μαθηματικό πρόβλημα του SVM.
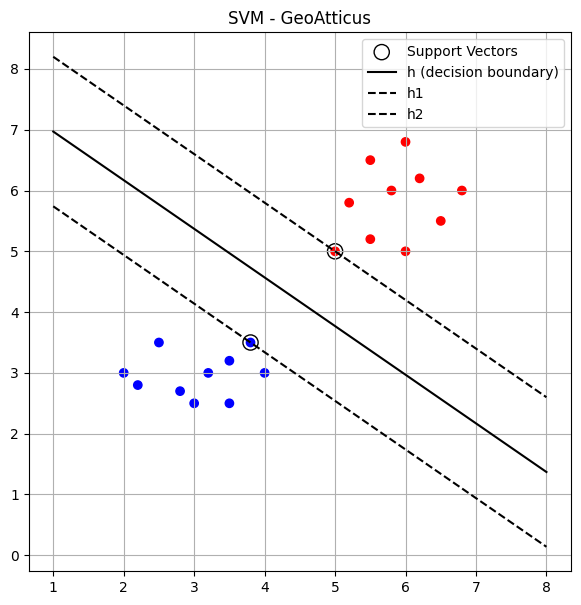
Ο Κώδικας
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
# =========================
# DATASET
# =========================
X = np.array([
[2, 3], [2.5, 3.5], [3, 2.5], [3.2, 3], [2.8, 2.7],
[3.5, 3.2], [2.2, 2.8], [3.8, 3.5], [4, 3], [3.5, 2.5],
[5, 5], [5.5, 5.2], [6, 5], [6.5, 5.5], [5.8, 6],
[6.2, 6.2], [5.2, 5.8], [6.8, 6], [5.5, 6.5], [6, 6.8],
])
y = np.array([0]*10 + [1]*10)
# =========================
# TRAIN SVM
# =========================
model = svm.SVC(kernel='linear', C=1e6) # μεγάλο C → hard margin
model.fit(X, y)
# =========================
# EXTRACT PARAMETERS
# =========================
w = model.coef_[0]
b = model.intercept_[0]
# =========================
# PLOT
# =========================
plt.figure(figsize=(7,7))
# scatter points
plt.scatter(X[:,0], X[:,1], c=y, cmap='bwr')
# support vectors
plt.scatter(model.support_vectors_[:,0],
model.support_vectors_[:,1],
s=120, facecolors='none', edgecolors='k', label='Support Vectors')
# δημιουργία γραμμών
x_vals = np.linspace(1, 8, 100)
# decision boundary: w.x + b = 0
y_vals = -(w[0]*x_vals + b) / w[1]
# margins: w.x + b = ±1
y_vals_m1 = -(w[0]*x_vals + b - 1) / w[1]
y_vals_m2 = -(w[0]*x_vals + b + 1) / w[1]
# plot lines
plt.plot(x_vals, y_vals, 'k-', label='h (decision boundary)')
plt.plot(x_vals, y_vals_m1, 'k--', label='h1')
plt.plot(x_vals, y_vals_m2, 'k--', label='h2')
plt.title("SVM - GeoAtticus")
plt.legend()
plt.grid(True)
plt.show()
Αποτέλεσμα
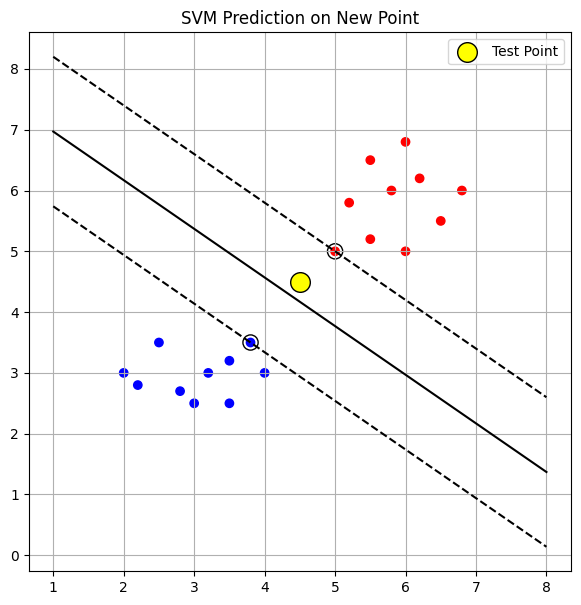
Εισαγωγή ενός test point
Στην συνέχεια εισάγουμε ένα test point στο σημείο (4.5, 4.5) με τον κώδικα:
# =========================
# TEST POINT
# =========================
test_point = np.array([[4.5, 4.5]])
prediction = model.predict(test_point)
print("Test point:", test_point)
print("Predicted class:", prediction[0])
Το αποτέλεσμα που επιστρέφει ο κώδικας είναι:
Test point: [[4.5 4.5]]
Predicted class: 1
Βιβλιογραφία
Dutt, S., Chandramouli, S., & Das, A. K. (2018). Machine learning. Pearson.
scikit‑learn. (2026). Support Vector Machines — scikit‑learn documentation. Ανακτήθηκε στις 24 Μαρτίου 2026, από https://scikit-learn.org/stable/modules/svm.html
Stanford Online. Stanford CS229: Machine Learning - Support Vector Machines | Lecture 6 (Autumn 2018) [Video]. YouTube. https://youtu.be/lDwow4aOrtg?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU
St-Aubin, A. (n.d.). An introduction to supervised machine learning. McGill University.