Machine Learning 17: Kernel Trick & Non-Linear SVM
Στο προηγούμενο άρθεο είδαμε ότι το Support Vector Machine βρίσκει την καλύτερη δυνατή ευθεία που χωρίζει τα δεδομένα σε δύο κατηγορίες.
Αυτό λειτουργεί πολύ καλά όταν τα δεδομένα είναι γραμμικά διαχωρίσιμα, δηλαδή όταν μπορούμε να τα χωρίσουμε με μια ευθεία.
Όμως, στην πραγματικότητα, τα περισσότερα datasets δεν έχουν αυτή τη μορφή.
Για παράδειγμα:
- Σημεία που σχηματίζουν κύκλο μέσα σε κύκλο
- Το κλασικό μοτίβο XOR
Σε αυτές τις περιπτώσεις, ένα γραμμικό μοντέλο αποτυγχάνει πλήρως.
Η βασική ιδέα
Αν δεν μπορούμε να χωρίσουμε τα δεδομένα με ευθεία στο αρχικό επίπεδο, τότε μπορούμε να κάνουμε κάτι πιο έξυπνο:
Δηλαδή, μεταφέρουμε τα δεδομένα σε έναν χώρο μεγαλύτερων διαστάσεων, όπου μπορεί πλέον να υπάρξει γραμμικός διαχωρισμός.
Σε αυτόν τον νέο χώρο, τα δεδομένα που πριν δεν χωρίζονταν, μπορούν τώρα να διαχωριστούν με ένα απλό hyperplane.
Το πρόβλημα
Η μετατροπή αυτή (mapping) μπορεί να είναι πολύ ακριβή υπολογιστικά, ειδικά όταν ο νέος χώρος έχει πολλές διαστάσεις.
Η λύση: Kernel Trick
Αντί να υπολογίζουμε ρητά τις νέες συντεταγμένες, χρησιμοποιούμε μια συνάρτηση (kernel) που υπολογίζει απευθείας τη “σχέση” μεταξύ δύο σημείων στον νέο χώρο.
Έτσι:
- Αποφεύγουμε τον μεγάλο υπολογιστικό φόρτο
- Διατηρούμε τη δύναμη των υψηλών διαστάσεων
- Μπορούμε να λύσουμε μη γραμμικά προβλήματα
Παράδειγμα
Σε αυτό το παράδειγμα έχουμε ένα σύνολο σημείων με κυκλική κατανομή μέσα σε ένα άλλο σύνολο σημείων που τα περικυκλώνει:
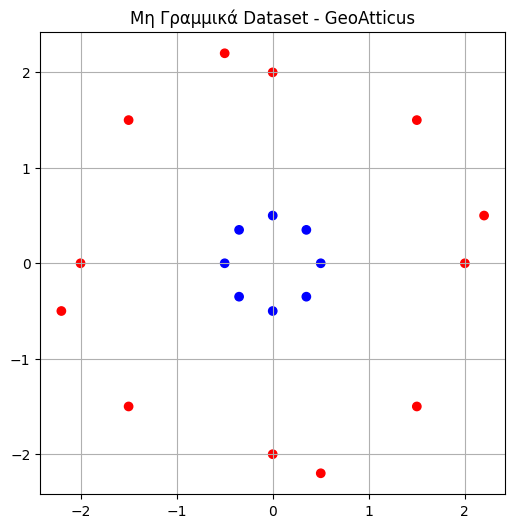
Η Λύση: Μη Γραμμικός Kernel (RBF)
Για να αντιμετωπίσουμε αυτό το πρόβλημα, χρησιμοποιούμε έναν μη γραμμικό kernel.
Ο πιο δημοφιλής είναι ο RBF (Radial Basis Function).
Αντί να προσπαθεί να χωρίσει τα δεδομένα με μια ευθεία, το μοντέλο λαμβάνει υπόψη του την απόσταση μεταξύ των σημείων.
Οι Παράμετροι του RBF Kernel
Όταν χρησιμοποιούμε τον RBF kernel, το μοντέλο εξαρτάται από δύο σημαντικές παραμέτρους:
- C
- gamma
Η παράμετρος C
Η παράμετρος C ελέγχει το πόσο αυστηρά θέλουμε να ταξινομήσουμε σωστά τα δεδομένα.
- Μικρό C → πιο "χαλαρό" μοντέλο, επιτρέπει λάθη αλλά είναι πιο απλό
- Μεγάλο C → προσπαθεί να ταξινομήσει σωστά όλα τα σημεία
Η παράμετρος gamma
Η παράμετρος gamma καθορίζει πόσο επηρεάζει κάθε σημείο τα γύρω του.
- Μικρό gamma → κάθε σημείο επηρεάζει μεγάλη περιοχή
- Μεγάλο gamma → κάθε σημείο επηρεάζει μόνο πολύ κοντινά σημεία
Η σωστή επιλογή των παραμέτρων C και gamma είναι κρίσιμη για την απόδοση του μοντέλου γιατί αν οι τιμές δεν είναι κατάλληλες το μοντέλο μπορεί να οδηγήσει σε underfitting ή σε overfitting.
Ο Κώδικας
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
# =========================
# DATASET
# =========================
X1 = np.array([
# inner circle (class 0)
[0.5, 0], [0, 0.5], [-0.5, 0], [0, -0.5],
[0.35, 0.35], [-0.35, 0.35], [-0.35, -0.35], [0.35, -0.35],
# outer circle (class 1)
[2, 0], [0, 2], [-2, 0], [0, -2],
[1.5, 1.5], [-1.5, 1.5], [-1.5, -1.5], [1.5, -1.5],
[2.2, 0.5], [-2.2, -0.5], [0.5, -2.2], [-0.5, 2.2]
])
y1 = np.array([0]*8 + [1]*12)
# =========================
# PLOTTING SVM
# =========================
def plot_svm(X, y, model, title):
plt.figure(figsize=(6,6))
# scatter
plt.scatter(X[:,0], X[:,1], c=y, cmap='bwr')
# support vectors
plt.scatter(model.support_vectors_[:,0],
model.support_vectors_[:,1],
s=120, facecolors='none', edgecolors='k',
label='Support Vectors')
# create grid
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx = np.linspace(xlim[0], xlim[1], 200)
yy = np.linspace(ylim[0], ylim[1], 200)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = model.decision_function(xy).reshape(XX.shape)
# decision boundary
ax.contour(XX, YY, Z, levels=[0])
plt.title(title)
plt.legend()
plt.grid(True)
plt.show()
# =========================
# RBF SVM
# =========================
rbf_model = svm.SVC(kernel='rbf', C=1.0, gamma='scale')
rbf_model.fit(X1, y1)
plot_svm(X1, y1, rbf_model,
"RBF SVM - GeoAtticus")
Η επιλογή gamma='scale' σημαίνει ότι η τιμή του gamma δεν ορίζεται χειροκίνητα, αλλά υπολογίζεται αυτόματα με βάση τα δεδομένα σύμφωνα με τον τύπο γ = 1 / (n_features · Var(X)). Δηλαδή εξαρτάται τόσο από τον αριθμό των χαρακτηριστικών όσο και από τη διασπορά των δεδομένων. Αυτό επιτρέπει στο μοντέλο να προσαρμόζεται δυναμικά: όταν τα δεδομένα είναι πιο απλωμένα (μεγάλη διασπορά), το gamma γίνεται μικρότερο και το όριο απόφασης είναι πιο ομαλό, ενώ όταν τα δεδομένα είναι πιο συγκεντρωμένα, το gamma αυξάνεται και το μοντέλο εστιάζει περισσότερο τοπικά.
Αποτέλεσμα
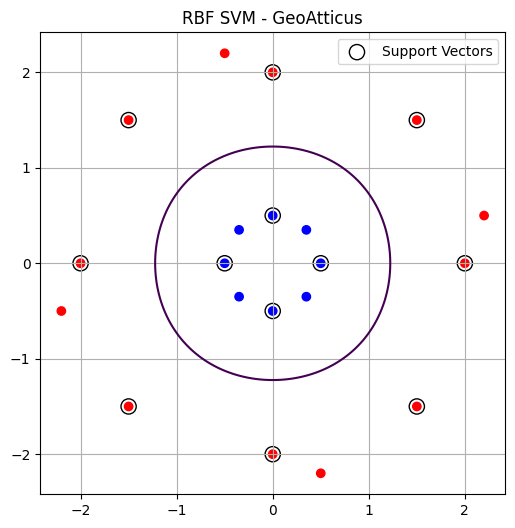
Test Data
Ας φέρουμε test data να δοκιμάσουμε την συμπεριφορά του μοντέλου σε νέα δεδομένα. Μέχρι στιγμής προγραμματίζαμε ένα δοκιμαστικό σημείο ενδεικτικά, όμως μια συνηθισμένη πρακτική είναι να να εισάγουμε το 20-25% των δεδομένων ως test data κάνοντας Data Split. Εδώ θα εισάγουμε έξι νέα σημεία.
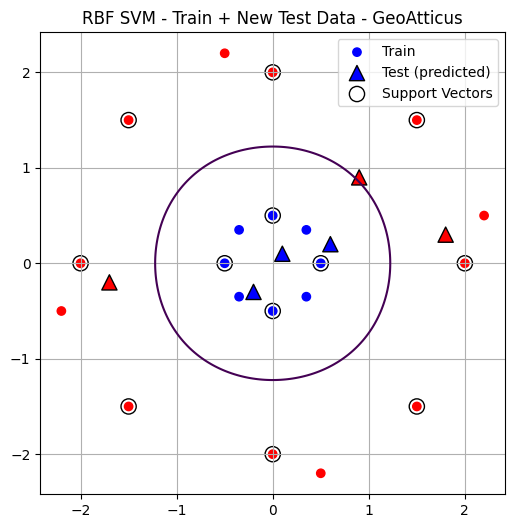
X_test = np.array([
[0.1, 0.1], # μέσα
[0.6, 0.2], # κοντά στο όριο
[1.8, 0.3], # έξω
[-0.2, -0.3], # μέσα
[-1.7, -0.2], # έξω
[0.9, 0.9], # borderline
])
y_pred = model.predict(X_test)
Point [0.1 0.1] -> Class 0
Point [0.6 0.2] -> Class 0
Point [1.8 0.3] -> Class 1
Point [-0.2 -0.3] -> Class 0
Point [-1.7 -0.2] -> Class 1
Point [0.9 0.9] -> Class 1
Βιβλιογραφία
Dutt, S., Chandramouli, S., & Das, A. K. (2018). Machine learning. Pearson.
scikit‑learn. (n.d.). Support Vector Machines — scikit‑learn documentation. Ανακτήθηκε στις 24 Μαρτίου 2026, από https://scikit-learn.org/stable/modules/svm.html
scikit‑learn. (n.d.). SVC. Ανακτήθηκε στις 24 Μαρτίου 2026, από https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
Stanford Online. Stanford CS229: Machine Learning - Support Vector Machines | Lecture 6 (Autumn 2018) [Video]. YouTube. https://youtu.be/lDwow4aOrtg?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU
St-Aubin, A. (n.d.). An introduction to supervised machine learning. McGill University.