Machine Learning 18: Classification με Decision Tree
Τι είναι τα Decision Trees
Τα Decision Trees (Δέντρα Απόφασης) είναι ένας από τους πιο απλούς και κατανοητούς αλγορίθμους της επιβλεπόμενης μάθησης (supervised learning). Χρησιμοποιούνται τόσο για classification όσο και για regression.
Η βασική ιδέα είναι ότι το μοντέλο μαθαίνει μια σειρά από κανόνες τύπου if–else, οι οποίοι χωρίζουν σταδιακά τα δεδομένα σε μικρότερα υποσύνολα. Κάθε διαχωρισμός βασίζεται σε ένα χαρακτηριστικό (feature), όπως για παράδειγμα οι συντεταγμένες ενός σημείου σε έναν χάρτη.
Το αποτέλεσμα είναι μια δομή που μοιάζει με δέντρο:
- Root node: το αρχικό σημείο (όλα τα δεδομένα)
- Internal nodes: τα σημεία όπου γίνεται κάποιος έλεγχος (π.χ. x < 50)
- Leaf nodes: οι τελικές αποφάσεις (η κλάση του δεδομένου)
Λειτουργία των Decision Trees
Τα Decision Trees βασίζονται σε μια επαναληπτική διαδικασία διαχωρισμού (splitting) του χώρου των δεδομένων. Σε κάθε βήμα, το μοντέλο επιλέγει ένα χαρακτηριστικό (feature) και μια τιμή κατωφλίου (threshold), ώστε να χωρίσει τα δεδομένα σε δύο υποσύνολα.
Οι διαχωρισμοί αυτοί είναι axis-aligned, δηλαδή της μορφής:
Η διαδικασία συνεχίζεται αναδρομικά σε κάθε υποσύνολο, μέχρι να ικανοποιηθεί κάποιο κριτήριο τερματισμού (π.χ. μέγιστο βάθος δέντρου ή καθαρότητα κόμβου).
Κριτήριο επιλογής split
Σε κάθε κόμβο, το Decision Tree επιλέγει το split που βελτιστοποιεί ένα μέτρο καθαρότητας (impurity). Στην υλοποίηση της Python μέσω της βιβλιοθήκης scikit-learn, χρησιμοποιείται προεπιλεγμένα το κριτήριο Gini impurity.
Ο αλγόριθμος εξετάζει πολλαπλά πιθανά thresholds για κάθε feature και επιλέγει εκείνο που μειώνει περισσότερο την αβεβαιότητα των κλάσεων στα παραγόμενα υποσύνολα.
Υλοποίηση με scikit-learn
Στη βιβλιοθήκη scikit-learn, ο αλγόριθμος υλοποιείται μέσω της κλάσης:
Κατά την εκπαίδευση, το μοντέλο κατασκευάζει το δέντρο επιλέγοντας διαδοχικά τα βέλτιστα splits σύμφωνα με το επιλεγμένο κριτήριο (π.χ. Gini ή entropy).
Ο χρήστης μπορεί να ελέγξει τη μορφή του δέντρου μέσω παραμέτρων όπως:
- max_depth: μέγιστο βάθος δέντρου
- min_samples_split: ελάχιστος αριθμός δειγμάτων για split
- criterion: μέτρο impurity (gini ή entropy)
Καθώς δεν έχει οριστεί διαφορετικό κριτήριο, το μοντέλο χρησιμοποιεί προεπιλεγμένα το Gini impurity για την επιλογή των splits.
Ο Κώδικας
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.tree import DecisionTreeClassifier, plot_tree
# 1. Dataset (fixed)
X, y = make_classification(
n_samples=200,
n_features=2,
n_redundant=0,
n_informative=2,
n_clusters_per_class=1,
class_sep=1.5,
random_state=42
)
# 2. Train Decision Tree
model = DecisionTreeClassifier(max_depth=2, random_state=42)
model.fit(X, y)
# 3. Plot decision boundary
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(
np.linspace(x_min, x_max, 300),
np.linspace(y_min, y_max, 300)
)
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8, 6))
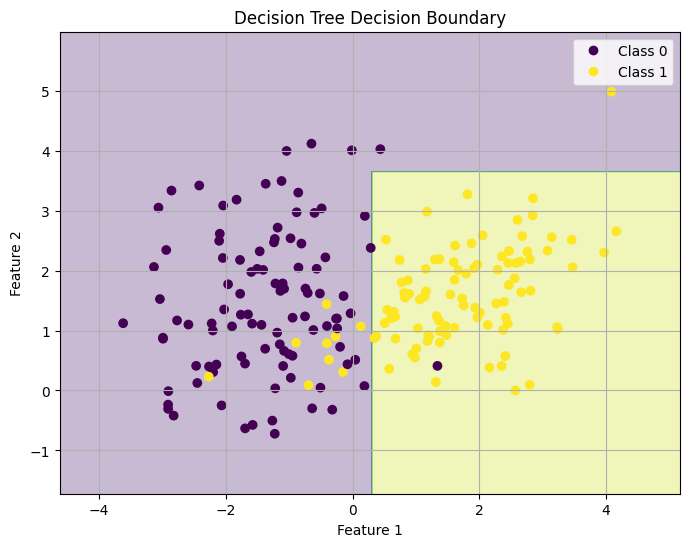
# background (decision regions)
plt.contourf(xx, yy, Z, alpha=0.3)
# points
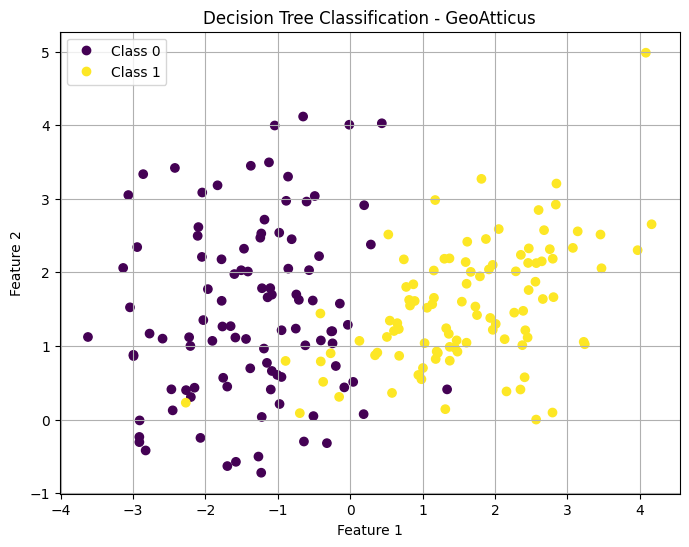
scatter = plt.scatter(X[:, 0], X[:, 1], c=y)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("Decision Tree Decision Boundary")
handles, labels = scatter.legend_elements()
plt.legend(handles, ["Class 0", "Class 1"])
plt.grid()
plt.show()
# 4. Plot the tree structure
plt.figure(figsize=(12, 8))
plot_tree(
model,
filled=True,
feature_names=["Feature 1", "Feature 2"],
class_names=["Class 0", "Class 1"]
)
plt.title("Decision Tree - GeoAtticus")
plt.show()
Βήμα-βήμα εκτέλεση του δέντρου
Το Decision Tree λειτουργεί σαν μια ακολουθία από ελέγχους if–else. Για κάθε νέο σημείο, το μοντέλο ξεκινά από τη ρίζα και ακολουθεί ένα μονοπάτι μέχρι να φτάσει σε ένα φύλλο.
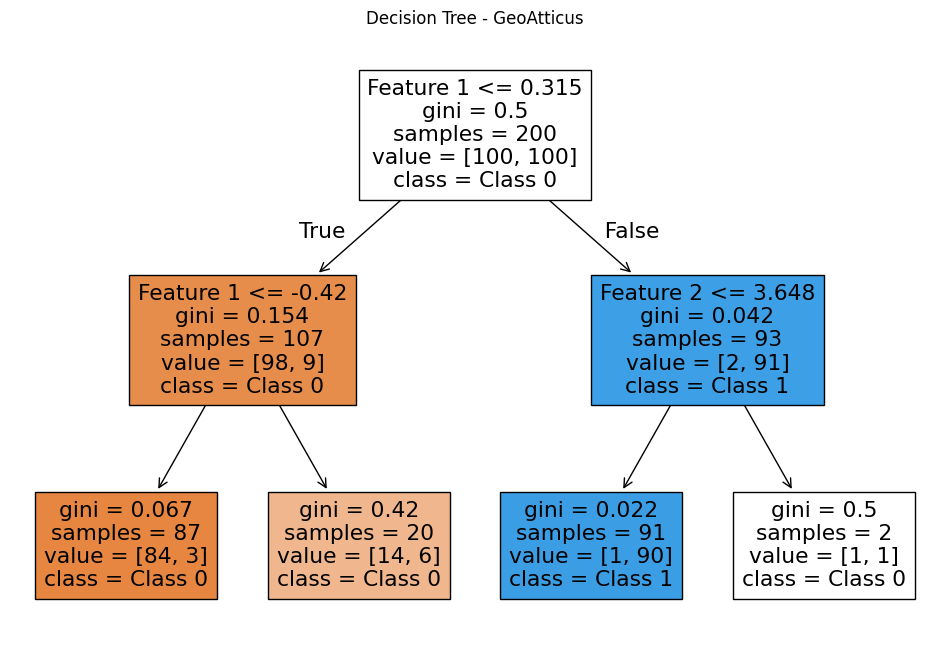
Το root του δέντρου αντιστοιχεί στο πρώτο split που εφαρμόζεται στα δεδομένα. Το Decision Tree εξετάζει όλα τα διαθέσιμα χαρακτηριστικά (features) και πολλαπλές πιθανές τιμές κατωφλίου (thresholds). Για κάθε πιθανό split, υπολογίζει ένα μέτρο καθαρότητας (impurity), όπως το Gini impurity, και επιλέγει εκείνο που οδηγεί στον καλύτερο διαχωρισμό των κλάσεων.
Στο συγκεκριμένο παράδειγμα, επιλέχθηκε το split:
καθώς αυτός ο διαχωρισμός μειώνει περισσότερο την αβεβαιότητα των δεδομένων σε σχέση με οποιονδήποτε άλλο πιθανό διαχωρισμό.
# Υπολογισμός Gini
def gini(y):
classes, counts = np.unique(y, return_counts=True)
probs = counts / counts.sum()
return 1 - np.sum(probs**2)
# Δοκιμή splits για Feature 1
feature_index = 0 # Feature 1
values = np.sort(X[:, feature_index])
# πιθανά thresholds (midpoints)
thresholds = (values[:-1] + values[1:]) / 2
best_gini = 1
best_t = None
print("Δοκιμή splits για Feature 1:\n")
for t in thresholds:
left_mask = X[:, feature_index] <= t
right_mask = X[:, feature_index] > t
y_left = y[left_mask]
y_right = y[right_mask]
# weighted gini
gini_split = (
len(y_left)/len(y) * gini(y_left) +
len(y_right)/len(y) * gini(y_right)
)
print(f"threshold = {t:.3f}, gini = {gini_split:.4f}")
if gini_split < best_gini:
best_gini = gini_split
best_t = t
print("\nΚαλύτερο split για Feature 1:")
print(f"threshold = {best_t:.3f}, gini = {best_gini:.4f}")
Αυτός ο κώδικας αν ενσωματωθεί στον βασικό επιστρέφει:
threshold = 0.315, gini = 0.1020
feature_index = 1 # Feature 2
values = np.sort(X[:, feature_index])
thresholds = (values[:-1] + values[1:]) / 2
best_gini = 1
best_t = None
print("\nΔοκιμή splits για Feature 2:\n")
for t in thresholds:
left_mask = X[:, feature_index] <= t
right_mask = X[:, feature_index] > t
y_left = y[left_mask]
y_right = y[right_mask]
gini_split = (
len(y_left)/len(y) * gini(y_left) +
len(y_right)/len(y) * gini(y_right)
)
print(f"threshold = {t:.3f}, gini = {gini_split:.4f}")
if gini_split < best_gini:
best_gini = gini_split
best_t = t
print("\nΚαλύτερο split για Feature 2:")
print(f"threshold = {best_t:.3f}, gini = {best_gini:.4f}")
Αυτός ο κώδικας αν ενσωματωθεί στον βασικό επιστρέφει:
threshold = 0.081, gini = 0.4695
Παράδειγμα 1
Έστω ένα σημείο με:
Feature 2 (δηλ y)= 0.5
Βήμα-βήμα:
2. Feature 1 ≤ -0.420 → ΝΑΙ → πάμε αριστερά
3. Φτάνουμε σε φύλλο → class = 0
Το σημείο ταξινομείται ως κλάση 0.
Παράδειγμα 2
Feature 2 = 2.0
2. Feature 2 ≤ 3.648 → ΝΑΙ → πάμε αριστερά
3. Φτάνουμε σε φύλλο → class = 1
Το σημείο ταξινομείται ως κλάση 1.
Παράδειγμα 3
Feature 2 = 5.0
2. Feature 2 ≤ 3.648 → ΟΧΙ → πάμε δεξιά
3. Φτάνουμε σε φύλλο → class = 0 (αβεβαιότητα 50%)
Σε αυτή την περίπτωση το μοντέλο καταλήγει σε φύλλο με πολύ λίγα δεδομένα, οπότε η πρόβλεψη έχει υψηλή αβεβαιότητα.
Αποτέλεσμα
Βιβλιογραφία
Dutt, S., Chandramouli, S., & Das, A. K. (2018). Machine learning. Pearson.
scikit‑learn. (n.d.). 1.10. Decision Trees. Ανακτήθηκε στις 28 Μαρτίου 2026, από https://scikit-learn.org/stable/modules/tree.html
Stanford Online. Stanford CS229: Machine Learning - Decision Trees and Ensemble Methods | Lecture 9 (Autumn 2018) [Video]. YouTube. https://youtu.be/wr9gUr-eWdA?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU
St-Aubin, A. (n.d.). An introduction to supervised machine learning. McGill University.