Training Sample: είναι ένα παράδειγμα δεδομένων που δίνουμε στο μοντέλο για να μάθει, μαζί με τη σωστή του απάντηση (label).
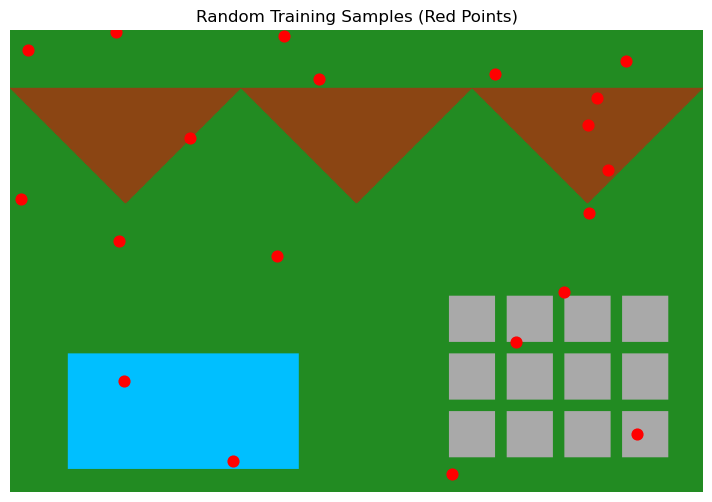
| # | x | y | R | G | B | label |
|---|---|---|---|---|---|---|
| 0 | 91 | 1 | 34 | 139 | 34 | 0 |
| 1 | 419 | 38 | 34 | 139 | 34 | 0 |
| 2 | 542 | 349 | 169 | 169 | 169 | 1 |
| 3 | 9 | 146 | 34 | 139 | 34 | 0 |
| 4 | 267 | 42 | 34 | 139 | 34 | 0 |
| 5 | 508 | 58 | 139 | 69 | 19 | 0 |
| 6 | 15 | 17 | 34 | 139 | 34 | 0 |
| 7 | 382 | 384 | 34 | 139 | 34 | 0 |
| 8 | 501 | 158 | 34 | 139 | 34 | 0 |
| 9 | 517 | 121 | 139 | 69 | 19 | 0 |
| 10 | 533 | 26 | 34 | 139 | 34 | 0 |
| 11 | 98 | 303 | 0 | 191 | 255 | 0 |
| 12 | 94 | 182 | 34 | 139 | 34 | 0 |
| 13 | 438 | 270 | 34 | 139 | 34 | 0 |
| 14 | 237 | 5 | 34 | 139 | 34 | 0 |
| 15 | 479 | 226 | 34 | 139 | 34 | 0 |
| 16 | 155 | 93 | 139 | 69 | 19 | 0 |
| 17 | 500 | 82 | 139 | 69 | 19 | 0 |
| 18 | 231 | 195 | 34 | 139 | 34 | 0 |
| 19 | 193 | 373 | 0 | 191 | 255 | 0 |
Empirical Risk: μετράει το μέσο σφάλμα ενός μοντέλου πάνω στα δεδομένα εκπαίδευσης. Ουσιαστικά, υπολογίζει πόσο συχνά οι προβλέψεις του μοντέλου αποκλίνουν από τις πραγματικές ετικέτες. Αν όλες οι προβλέψεις είναι σωστές, ο εμπειρικός κίνδυνος είναι 0.
Στην περίπτωσή μας, όλες οι προβλέψεις του μοντέλου είναι σωστές. Ο εμπειρικός κίνδυνος υπολογίζεται με τον τύπο:
Εδώ:
- N = 20 είναι ο αριθμός των παραδειγμάτων εκπαίδευσης.
- yi είναι οι πραγματικές ετικέτες.
- f(xi) είναι οι προβλέψεις του μοντέλου.
- L(yi, f(xi)) είναι η συνάρτηση απώλειας (0 αν η πρόβλεψη είναι σωστή, 1 αν είναι λάθος).
Επειδή όλες οι προβλέψεις είναι σωστές, κάθε L(yi, f(xi)) = 0.
Επομένως, ο εμπειρικός κίνδυνος για το μοντέλο μας είναι 0.
Σημείωση: Ένας εμπειρικός κίνδυνος 0 σημαίνει ότι το μοντέλο ταιριάζει τέλεια με τα δεδομένα εκπαίδευσης, αλλά δεν εγγυάται ότι θα λειτουργεί τέλεια σε νέα δεδομένα.
Αλλάζουμε επίτηδες το label σε δύο samples, στο νο9 και στο νο15 για να δουμε πως επηρρεάζεται το empirical risk.
| # | x | y | R | G | B | label |
|---|---|---|---|---|---|---|
| 0 | 91 | 1 | 34 | 139 | 34 | 0 |
| 1 | 419 | 38 | 34 | 139 | 34 | 0 |
| 2 | 542 | 349 | 169 | 169 | 169 | 1 |
| 3 | 9 | 146 | 34 | 139 | 34 | 0 |
| 4 | 267 | 42 | 34 | 139 | 34 | 0 |
| 5 | 508 | 58 | 139 | 69 | 19 | 0 |
| 6 | 15 | 17 | 34 | 139 | 34 | 0 |
| 7 | 382 | 384 | 34 | 139 | 34 | 0 |
| 8 | 501 | 158 | 34 | 139 | 34 | 0 |
| 9 | 517 | 121 | 139 | 69 | 19 | 1 |
| 10 | 533 | 26 | 34 | 139 | 34 | 0 |
| 11 | 98 | 303 | 0 | 191 | 255 | 0 |
| 12 | 94 | 182 | 34 | 139 | 34 | 0 |
| 13 | 438 | 270 | 34 | 139 | 34 | 0 |
| 14 | 237 | 5 | 34 | 139 | 34 | 0 |
| 15 | 479 | 226 | 34 | 139 | 34 | 1 |
| 16 | 155 | 93 | 139 | 69 | 19 | 0 |
| 17 | 500 | 82 | 139 | 69 | 19 | 0 |
| 18 | 231 | 195 | 34 | 139 | 34 | 0 |
| 19 | 193 | 373 | 0 | 191 | 255 | 0 |
Τώρα το empirical risk γίνεται:
Remp(f) = (1 + 1 + 0 + 0 + 0 + 0 + 0 + 0 + 0 + 0) / 10 = 2 / 10 = 0.2 (20%)
Άρα το μοντέλο κάνει λάθος στο 20% των pixels.
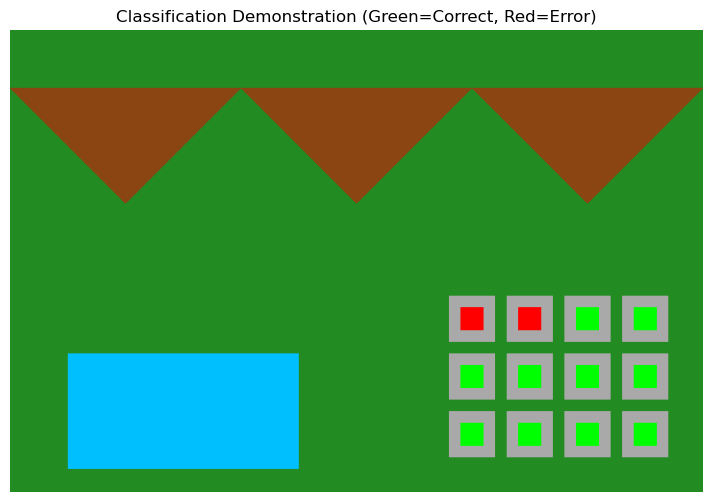
Με βάση τον λάθος πίνακα δημιουργήσαμε έναν απλό classifier (προς το παρόν είναι black box, δεν μας νοιάζει), ο οποίος μάντεψε σωστά όλα τα αστικά block εκτός από δύο. Με πράσινο είναι αυτά που έγιναν classification ορθά και με κόκκινο τα λάθος.
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding machine learning: From theory to algorithms. Cambridge University Press