Στην προηγούμενη ενότητα μελετήσαμε τη σχέση μεταξύ τάσης (stress) και παραμόρφωσης (strain) σε ένα πείραμα μηχανικής πετρωμάτων.
Η βασική φυσική σχέση είναι ο νόμος του Hooke:
σ = E · ε
Στην ενότητα ML6 υπολογίσαμε το μέτρο Young χρησιμοποιώντας τη μέθοδο των ελαχίστων τετραγώνων (OLS).
Τώρα θα δούμε πώς το ίδιο πρόβλημα διατυπώνεται στο πλαίσιο του Machine Learning.
Χρησιμοποιούμε τα ίδια δεδομένα του πειράματος:
| Strain ε | Stress σ (Pa) |
|---|---|
| 0.0005 | 11200000 |
| 0.0010 | 20500000 |
| 0.0015 | 30800000 |
| 0.0020 | 39900000 |
| 0.0025 | 51100000 |
| 0.0030 | 59400000 |
Στο Machine Learning τα δεδομένα εκπαίδευσης (training data) περιγράφονται με συγκεκριμένη μαθηματική σημειογραφία.
Στο πείραμά μας έχουμε:
Κάθε γραμμή του πίνακα είναι ένα training example:
| i | x(i) = strain | y(i) = stress |
|---|---|---|
| 1 | 0.0005 | 11200000 |
| 2 | 0.0010 | 20500000 |
| 3 | 0.0015 | 30800000 |
| 4 | 0.0020 | 39900000 |
| 5 | 0.0025 | 51100000 |
| 6 | 0.0030 | 59400000 |
Το μοντέλο που θέλουμε να μάθει ο αλγόριθμος είναι:
hθ(x) = θx
όπου:
Στην πραγματικότητα η παράμετρος θ αντιστοιχεί στο Young's modulus.
Ο στόχος του Machine Learning είναι να βρει την τιμή του θ που κάνει τις προβλέψεις του μοντέλου όσο το δυνατόν πιο κοντά στις πραγματικές μετρήσεις stress.
Δηλαδή θέλουμε να ελαχιστοποιήσουμε το σφάλμα μεταξύ:
Στην επόμενη ενότητα θα δούμε πώς αυτό γίνεται με τον αλγόριθμο:
Ο Gradient Descent βρίσκει σταδιακά την τιμή του θ που ελαχιστοποιεί το σφάλμα του μοντέλου.
Για να μπορέσουμε να βρούμε την καλύτερη τιμή της παραμέτρου θ, πρέπει πρώτα να μετρήσουμε πόσο καλές είναι οι προβλέψεις του μοντέλου μας.
Αυτό γίνεται με τη συνάρτηση κόστους (cost function).
Στην απλή γραμμική παλινδρόμηση η συνάρτηση κόστους ορίζεται ως:
J(θ) = (1 / 2m) Σ (hθ(x(i)) − y(i))²
όπου:
Η συνάρτηση κόστους μετρά το μέσο τετραγωνικό σφάλμα (mean squared error) μεταξύ των πραγματικών τιμών και των προβλέψεων του μοντέλου. Αποκαλείται και Mean Squared Error Loss.
Για το παράδειγμα του νόμου του Hooke έχουμε:
hθ(x) = θx
Άρα η συνάρτηση κόστους γίνεται:
J(θ) = (1 / 2m) Σ (θx(i) − y(i))²
Δοκιμάζοντας διαφορετικές τιμές του θ μπορούμε να υπολογίσουμε την τιμή της J(θ) για κάθε περίπτωση.
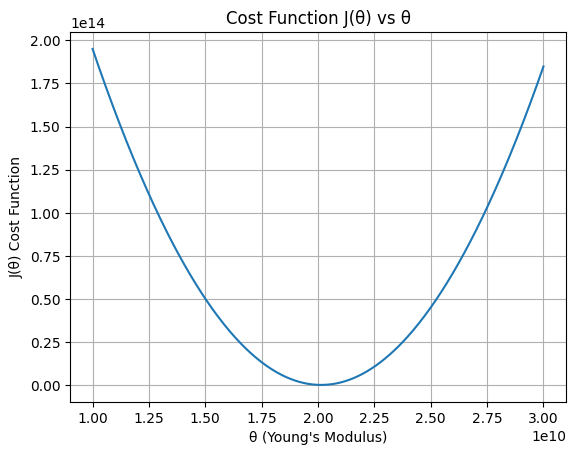
Με τη βοήθεια ενός προγράμματος Python υπολογίσαμε τη συνάρτηση κόστους για πολλές διαφορετικές τιμές του θ και σχεδιάσαμε το γράφημα της J(θ).
Το γράφημα της J(θ) έχει σχήμα παραβολής.
Για διαφορετικές τιμές της παραμέτρου θ το σφάλμα του μοντέλου αλλάζει.
Το χαμηλότερο σημείο της καμπύλης ονομάζεται minimum της cost function.
Η τιμή του θ στο σημείο αυτό είναι η καλύτερη δυνατή παράμετρος για το μοντέλο μας.
Στο παράδειγμα του πειράματος η τιμή αυτή αντιστοιχεί περίπου στο:
θ ≈ 2 × 10¹⁰ Pa
δηλαδή περίπου στο Young's modulus που υπολογίσαμε στην προηγούμενη ενότητα με τη μέθοδο OLS.
Θέλουμε να βρούμε την τιμή της παραμέτρου θ που ελαχιστοποιεί τη συνάρτηση κόστους:
min J(θ)
Για να βρούμε αυτό το ελάχιστο χρησιμοποιούμε έναν αλγόριθμο που ονομάζεται:
Στην επόμενη ενότητα θα δούμε πώς ο Gradient Descent βρίσκει σταδιακά την τιμή του θ που ελαχιστοποιεί τη συνάρτηση κόστους.
Το πρόβλημα που θέλουμε να λύσουμε είναι το εξής:
min J(θ)
Δηλαδή θέλουμε να βρούμε την τιμή της παραμέτρου θ που ελαχιστοποιεί τη συνάρτηση κόστους.
Ο πιο συνηθισμένος αλγόριθμος για αυτό το πρόβλημα είναι ο Gradient Descent.
Φανταστείτε ότι βρισκόμαστε σε ένα βουνό μέσα σε ομίχλη και θέλουμε να φτάσουμε στο χαμηλότερο σημείο της κοιλάδας.
Δεν βλέπουμε όλο το τοπίο, αλλά μπορούμε να αισθανθούμε την κλίση του εδάφους κάτω από τα πόδια μας.
Σε κάθε βήμα κινούμαστε προς την κατεύθυνση όπου το έδαφος κατεβαίνει περισσότερο.
Ξεκινάμε από μια αρχική τιμή της παραμέτρου:
θ0
Η τιμή αυτή μπορεί να είναι τυχαία.
Υπολογίζουμε την παράγωγο της συνάρτησης κόστους ως προς τη παράμετρο θ:
∂J(θ) / ∂θ
Η παράγωγος αυτή δείχνει την κατεύθυνση στην οποία αυξάνεται η συνάρτηση κόστους.
Για να μειώσουμε το σφάλμα, κινούμαστε προς την αντίθετη κατεύθυνση του gradient.
Η ενημέρωση της παραμέτρου γίνεται με τον κανόνα:
θ := θ − α ∂J(θ) / ∂θ
όπου:
Η διαδικασία επαναλαμβάνεται πολλές φορές:
Μετά από αρκετές επαναλήψεις η παράμετρος συγκλίνει προς το σημείο όπου η συνάρτηση κόστους είναι ελάχιστη.
Ο Gradient Descent σταματά όταν:
∂J(θ) / ∂θ ≈ 0
Στο σημείο αυτό έχουμε φτάσει σε ένα minimum της cost function.
Στο πρόβλημα της εκτίμησης του Young's modulus η παράμετρος που θέλουμε να βρούμε είναι το: Θ
Ο Gradient Descent ξεκινά από μια αρχική τιμή και προσαρμόζει σταδιακά το θ μέχρι οι προβλέψεις του μοντέλου να ταιριάζουν όσο το δυνατόν καλύτερα στα πειραματικά δεδομένα stress–strain.
Για να εφαρμόσουμε τον αλγόριθμο Gradient Descent στο παράδειγμα του νόμου του Hooke μπορούμε να χρησιμοποιήσουμε το ακόλουθο πρόγραμμα Python.
import numpy as np
import matplotlib.pyplot as plt
# strain
X = np.array([0.0005,0.0010,0.0015,0.0020,0.0025,0.0030]).reshape(-1,1)
# stress in MPa
y = np.array([11.2,20.5,30.8,39.9,51.1,59.4])
theta = 0.0
l_rate = 5000
rep = 200
losses = []
for _ in range(rep):
preds = theta * X.ravel()
err = preds - y
loss = (err**2).mean()/2
losses.append(loss)
dtheta = (X.ravel()*err).mean()
theta -= l_rate*dtheta
print("Estimated Young Modulus:",theta)
Ο παραπάνω κώδικας υλοποιεί τον αλγόριθμο Gradient Descent για να υπολογίσει το μέτρο Young από τα πειραματικά δεδομένα. Ας εξετάσουμε τα βασικά του μέρη.
X = np.array([0.0005,0.0010,0.0015,0.0020,0.0025,0.0030]) y = np.array([11.2,20.5,30.8,39.9,51.1,59.4])
Το διάνυσμα X περιέχει τις τιμές της παραμόρφωσης (strain) ενώ το διάνυσμα y περιέχει τις αντίστοιχες τιμές της τάσης (stress).
Κάθε ζεύγος:
(x(i), y(i))
αποτελεί ένα training example.
theta = 0.0
Ο αλγόριθμος ξεκινά από μια αρχική τιμή της παραμέτρου θ.
Στο πρόβλημά μας η παράμετρος αυτή αντιστοιχεί στο Young's modulus.
l_rate = 5000
Το learning rate καθορίζει το μέγεθος του βήματος που κάνει ο αλγόριθμος σε κάθε επανάληψη.
Αν το learning rate είναι πολύ μεγάλο, ο αλγόριθμος μπορεί να γίνει ασταθής. Αν είναι πολύ μικρό, η σύγκλιση γίνεται πολύ αργή.
rep = 200
Ο Gradient Descent είναι επαναληπτικός αλγόριθμος. Σε κάθε επανάληψη ενημερώνεται η τιμή της παραμέτρου.
preds = theta * X
Το μοντέλο που χρησιμοποιούμε είναι:
hθ(x) = θx
Η μεταβλητή preds περιέχει τις προβλέψεις του μοντέλου.
err = preds - y
Το σφάλμα είναι η διαφορά μεταξύ της πραγματικής τιμής και της πρόβλεψης.
loss = (err**2).mean()/2
Η συνάρτηση κόστους είναι:
J(θ) = (1 / 2m) Σ (hθ(x(i)) − y(i))²
Η συνάρτηση αυτή μετρά το μέσο τετραγωνικό σφάλμα του μοντέλου.
dtheta = (X * err).mean()
Το gradient δείχνει προς την κατεύθυνση στην οποία αυξάνεται περισσότερο η συνάρτηση κόστους.
theta -= l_rate * dtheta
Η ενημέρωση της παραμέτρου γίνεται σύμφωνα με τον κανόνα του Gradient Descent:
θ := θ − α ∂J(θ)/∂θ
Με αυτό το βήμα ο αλγόριθμος κινείται προς την κατεύθυνση όπου η συνάρτηση κόστους μειώνεται.
Μετά από αρκετές επαναλήψεις ο αλγόριθμος συγκλίνει σε μια τιμή της παραμέτρου:
θ ≈ 20000 MPa
η οποία αντιστοιχεί στο Young's modulus του υλικού που μελετήσαμε.
Montgomery, D. C., Peck, E. A., & Vining, G. G. (2021). Introduction to linear regression analysis (6th ed.). Wiley.
Stanford Online. Stanford CS229: Machine Learning - Linear Regression and Gradient Descent | Lecture 2 (Autumn 2018) [Video]. YouTube. https://www.youtube.com/watch?v=4b4MUYve_U8&t=3051s
St-Aubin, A. (n.d.). An introduction to supervised machine learning. McGill University.