Η υδροστατική πίεση είναι η πίεση που ασκεί ένα υγρό λόγω του βάρους της στήλης του. Η πίεση αυξάνεται γραμμικά με το βάθος.
P = ρ g h
Για το νερό περίπου:
P ≈ 9.81 h (kPa/m)
Το μοντέλο που θα εκπαιδεύσουμε είναι:
P = w h + b
Το SGD θα μάθει τις παραμέτρους w και b από τα δεδομένα.
| ID | Depth (m) | Pressure (kPa) |
|---|---|---|
| 1 | 0.1 | 0.97 |
| 2 | 0.2 | 2.01 |
| 3 | 0.3 | 2.85 |
| 4 | 0.4 | 3.94 |
| 5 | 0.5 | 4.88 |
| 6 | 0.6 | 5.93 |
| 7 | 0.7 | 6.84 |
| 8 | 0.8 | 7.82 |
| 9 | 0.9 | 8.97 |
| 10 | 1.0 | 9.76 |
| 11 | 1.1 | 10.82 |
| 12 | 1.2 | 11.78 |
| 13 | 1.3 | 12.70 |
| 14 | 1.4 | 13.89 |
| 15 | 1.5 | 14.71 |
| 16 | 1.6 | 15.82 |
| 17 | 1.7 | 16.63 |
| 18 | 1.8 | 17.77 |
| 19 | 1.9 | 18.69 |
| 20 | 2.0 | 19.71 |
| 21 | 2.1 | 20.55 |
| 22 | 2.2 | 21.70 |
| 23 | 2.3 | 22.61 |
| 24 | 2.4 | 23.63 |
| 25 | 2.5 | 24.60 |
| 26 | 2.6 | 25.48 |
| 27 | 2.7 | 26.70 |
| 28 | 2.8 | 27.42 |
| 29 | 2.9 | 28.61 |
| 30 | 3.0 | 29.50 |
| 31 | 3.1 | 30.48 |
| 32 | 3.2 | 31.33 |
| 33 | 3.3 | 32.58 |
| 34 | 3.4 | 33.37 |
| 35 | 3.5 | 34.44 |
| 36 | 3.6 | 35.37 |
| 37 | 3.7 | 36.41 |
| 38 | 3.8 | 37.12 |
| 39 | 3.9 | 38.25 |
| 40 | 4.0 | 39.33 |
| 41 | 4.1 | 40.12 |
| 42 | 4.2 | 41.36 |
| 43 | 4.3 | 42.22 |
| 44 | 4.4 | 43.29 |
| 45 | 4.5 | 44.09 |
| 46 | 4.6 | 45.23 |
| 47 | 4.7 | 46.15 |
| 48 | 4.8 | 47.21 |
| 49 | 4.9 | 48.10 |
| 50 | 5.0 | 49.07 |
| 51 | 5.1 | 50.15 |
| 52 | 5.2 | 51.11 |
| 53 | 5.3 | 52.06 |
| 54 | 5.4 | 53.23 |
| 55 | 5.5 | 53.99 |
| 56 | 5.6 | 55.02 |
| 57 | 5.7 | 56.18 |
| 58 | 5.8 | 56.99 |
| 59 | 5.9 | 58.00 |
| 60 | 6.0 | 58.96 |
| 61 | 6.1 | 60.02 |
| 62 | 6.2 | 60.86 |
| 63 | 6.3 | 61.99 |
| 64 | 6.4 | 62.74 |
| 65 | 6.5 | 63.93 |
| 66 | 6.6 | 64.67 |
| 67 | 6.7 | 65.85 |
| 68 | 6.8 | 66.74 |
| 69 | 6.9 | 67.70 |
| 70 | 7.0 | 68.64 |
| 71 | 7.1 | 69.82 |
| 72 | 7.2 | 70.53 |
| 73 | 7.3 | 71.67 |
| 74 | 7.4 | 72.70 |
| 75 | 7.5 | 73.51 |
| 76 | 7.6 | 74.70 |
| 77 | 7.7 | 75.45 |
| 78 | 7.8 | 76.63 |
| 79 | 7.9 | 77.44 |
| 80 | 8.0 | 78.55 |
| 81 | 8.1 | 79.53 |
| 82 | 8.2 | 80.33 |
| 83 | 8.3 | 81.64 |
| 84 | 8.4 | 82.21 |
| 85 | 8.5 | 83.45 |
| 86 | 8.6 | 84.19 |
| 87 | 8.7 | 85.34 |
| 88 | 8.8 | 86.26 |
| 89 | 8.9 | 87.19 |
| 90 | 9.0 | 88.41 |
| 91 | 9.1 | 89.15 |
| 92 | 9.2 | 90.32 |
| 93 | 9.3 | 91.18 |
| 94 | 9.4 | 92.31 |
| 95 | 9.5 | 93.26 |
| 96 | 9.6 | 94.12 |
| 97 | 9.7 | 95.31 |
| 98 | 9.8 | 96.02 |
| 99 | 9.9 | 97.29 |
| 100 | 10.0 | 98.04 |
import numpy as np
import matplotlib.pyplot as plt
# Dataset (ίδιο με τον πίνακα πάνω)
depth = np.array([
0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0,
1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9,2.0,
2.1,2.2,2.3,2.4,2.5,2.6,2.7,2.8,2.9,3.0,
3.1,3.2,3.3,3.4,3.5,3.6,3.7,3.8,3.9,4.0,
4.1,4.2,4.3,4.4,4.5,4.6,4.7,4.8,4.9,5.0,
5.1,5.2,5.3,5.4,5.5,5.6,5.7,5.8,5.9,6.0,
6.1,6.2,6.3,6.4,6.5,6.6,6.7,6.8,6.9,7.0,
7.1,7.2,7.3,7.4,7.5,7.6,7.7,7.8,7.9,8.0,
8.1,8.2,8.3,8.4,8.5,8.6,8.7,8.8,8.9,9.0,
9.1,9.2,9.3,9.4,9.5,9.6,9.7,9.8,9.9,10.0
])
pressure = np.array([
1.2,1.9,2.8,4.3,4.9,6.2,6.7,8.0,9.3,9.9,
10.5,11.6,12.9,13.1,15.0,15.7,16.5,17.8,18.3,19.9,
20.4,21.8,22.1,23.9,24.3,25.8,26.7,27.2,28.5,29.7,
30.1,31.8,32.5,33.2,34.9,35.1,36.4,37.6,38.1,39.4,
40.5,41.3,42.6,43.9,44.0,45.2,46.8,47.1,48.3,49.6,
50.2,51.4,52.7,53.5,54.8,55.0,56.9,57.1,58.2,59.4,
60.3,61.7,62.1,63.9,64.5,65.6,66.2,67.8,68.0,69.5,
70.4,71.3,72.9,73.1,74.6,75.3,76.8,77.2,78.4,79.6,
80.3,81.8,82.6,83.5,84.7,85.0,86.4,87.3,88.8,89.1,
90.2,91.5,92.4,93.6,94.1,95.7,96.2,97.4,98.5,99.1
])
# αρχικές τιμές
w = 0
b = 0
learning_rate = 0.0001
epochs = 50
n = len(depth)
for epoch in range(epochs):
for i in range(n):
x = depth[i]
y = pressure[i]
y_pred = w*x + b
dw = -2*x*(y - y_pred)
db = -2*(y - y_pred)
w = w - learning_rate*dw
b = b - learning_rate*db
print("Learned slope:", w)
print("Learned bias:", b)
# visualization
plt.scatter(depth, pressure)
plt.plot(depth, w*depth + b)
plt.xlabel("Depth (m)")
plt.ylabel("Pressure")
plt.title("SGD Linear Regression")
plt.show()
Χρησιμοποιούμε τις βιβλιοθήκες NumPy και Matplotlib για αριθμητικούς υπολογισμούς και γραφήματα.
Οι πίνακες depth και pressure περιέχουν τις τιμές από τον πίνακα δεδομένων του μαθήματος.
Το γραμμικό μοντέλο έχει τη μορφή:
P = w · h + b
w = 0 b = 0
Στην αρχή οι παράμετροι είναι τυχαίες ή μηδενικές. Το μοντέλο δεν γνωρίζει ακόμα τη σχέση μεταξύ βάθους και πίεσης.
Το learning rate καθορίζει πόσο μεγάλο βήμα θα κάνει το gradient descent.
learning_rate = 0.001
Αν είναι πολύ μεγάλο η εκπαίδευση γίνεται ασταθής. Αν είναι πολύ μικρό η εκπαίδευση γίνεται πολύ αργή.
Η εκπαίδευση γίνεται με δύο βρόχους.
for epoch in range(epochs):
for i in range(n):
Ο εξωτερικός βρόχος επαναλαμβάνει την εκπαίδευση πολλές φορές (epochs). Ο εσωτερικός βρόχος περνάει από κάθε δείγμα του dataset.
Στο Stochastic Gradient Descent η ενημέρωση των παραμέτρων γίνεται για κάθε δείγμα ξεχωριστά.
y_pred = w*x + b
Το μοντέλο υπολογίζει την προβλεπόμενη πίεση για το συγκεκριμένο βάθος.
Η συνάρτηση σφάλματος για ένα δείγμα είναι:
L = (y - y_pred)^2
και η προβλεπόμενη τιμή:
y_pred = w * x + b
Θέλουμε:
∂L/∂w = ∂/∂w (y - (w * x + b))^2
Με τον κανόνα της αλυσίδας:
u = y - (w * x + b) ∂L/∂w = 2 * u * ∂u/∂w ∂u/∂w = -x ∂L/∂w = -2 * x * (y - y_pred)
∂L/∂b = 2 * (y - y_pred) * ∂(y - (w*x+b))/∂b ∂(y - (w*x+b))/∂b = -1 ∂L/∂b = -2 * (y - y_pred)
dw = -2*x*(y - y_pred) db = -2*(y - y_pred)
Το gradient δείχνει προς ποια κατεύθυνση πρέπει να αλλάξουν οι παράμετροι ώστε να μειωθεί το σφάλμα.
w = w - learning_rate*dw b = b - learning_rate*db
Οι παράμετροι ενημερώνονται ώστε το μοντέλο να προσεγγίζει καλύτερα τα δεδομένα.
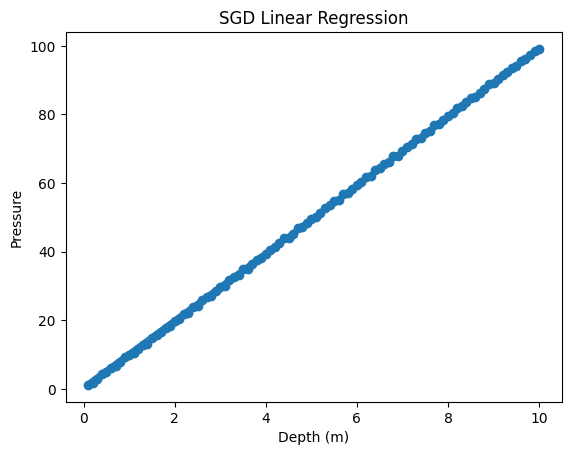
plt.scatter(depth,pressure) plt.plot(depth,w*depth+b)
Το γράφημα δείχνει:
Αν η εκπαίδευση έχει γίνει σωστά, η γραμμή θα προσεγγίζει τη φυσική σχέση της υδροστατικής πίεσης.
Ας δούμε αναλυτικά **τρία βήματα** του Stochastic Gradient Descent για ένα μόνο δείγμα από το dataset:
Το μοντέλο έχει τη μορφή:
P = w * h + b
Αρχικά οι παράμετροι είναι:
w = 0
b = 0
Για το πρώτο δείγμα (βάθος h = 0.1 m, πίεση P = 0.97 kPa):
y_pred = w * h + b = 0 * 0.1 + 0 = 0
Προβλεπόμενη πίεση: 0 kPa.
Υπολογίζουμε πόσο πρέπει να αλλάξουν οι παράμετροι για να μειωθεί το σφάλμα:
dw = -2 * h * (y - y_pred)
db = -2 * (y - y_pred)
Αντικαθιστούμε:
dw = -2 * 0.1 * (0.97 - 0) = -0.194
db = -2 * (0.97 - 0) = -1.94
Το gradient μας λέει προς ποια κατεύθυνση πρέπει να κινηθούμε.
Με ένα learning rate lr = 0.01:
w = w - lr * dw = 0 - 0.01 * (-0.194) = 0.00194
b = b - lr * db = 0 - 0.01 * (-1.94) = 0.0194
Μετά το επόμενο δείγμα, επαναλαμβάνουμε τα ίδια βήματα, και σιγά-σιγά η γραμμή πλησιάζει τα πραγματικά δεδομένα.
Δείγμα: x = 0.2, y = 2.01
Παράμετροι μετά από iteration 1: w = 0.00194, b = 0.0194
y_pred = w*x + b = 0.00194*0.2 + 0.0194 ≈ 0.019788 dw = -2 * 0.2 * (2.01 - 0.019788) ≈ -0.796 db = -2 * (2.01 - 0.019788) ≈ -3.9804 w_new = 0.00194 - 0.01*(-0.796) ≈ 0.00990 b_new = 0.0194 - 0.01*(-3.9804) ≈ 0.0592
Δείγμα: x = 0.3, y = 2.85
Παράμετροι: w = 0.00990, b = 0.0592
y_pred = w*x + b = 0.00990*0.3 + 0.0592 ≈ 0.06217 dw = -2 * 0.3 * (2.85 - 0.06217) ≈ -1.686 db = -2 * (2.85 - 0.06217) ≈ -5.5757 w_new = 0.00990 - 0.01*(-1.686) ≈ 0.02676 b_new = 0.0592 - 0.01*(-5.5757) ≈ 0.11495
Το ίδιο βήμα εφαρμόζεται σε όλα τα δείγματα. Με κάθε iteration (epoch), η γραμμή πλησιάζει σταδιακά όλα τα σημεία του dataset.
St-Aubin, A. (n.d.). An introduction to supervised machine learning. McGill University.