Neural Networks 2: Εκπαίδευση Νευρώνα (Perceptron) σε Python (πύλη AND)
Το perceptron είναι ο πιο απλός τύπος τεχνητού νευρώνα. Το two input, single neuron perceptron, παίρνει εισόδους (x1, x2), τις πολλαπλασιάζει με βάρη, προσθέτει ένα bias και περνά το αποτέλεσμα από μια συνάρτηση ενεργοποίησης (activation function). Αν το αποτέλεσμα είναι πάνω από ένα όριο, δίνει έξοδο 1, αλλιώς 0. Με αυτόν τον τρόπο μπορεί να μάθει απλές λογικές πράξεις όπως AND, OR.
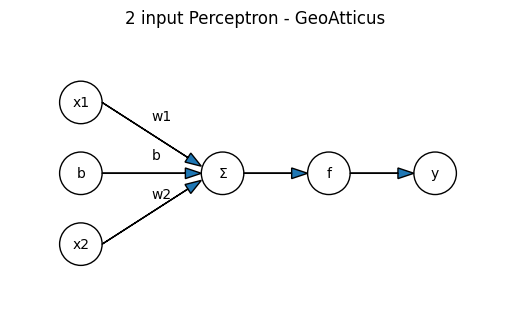
Ακολουθεί ένα πολύ απλό παράδειγμα σε Python, όπου ένας νευρώνας μαθαίνει τη λογική πράξη AND. Το μοντέλο προσαρμόζει τα βάρη και το bias ώστε να δίνει σωστές εξόδους.
Η συνάρτηση ενεργοποίησης που χρησιμοποιούμε ονομάζεται hardlim (hard limit)
και είναι υπεύθυνη για την τελική απόφαση του νευρώνα. Αρχικά υπολογίζεται το γραμμικό άθροισμα:
n = w₁x₁ + w₂x₂ + b
Στη συνέχεια εφαρμόζεται η συνάρτηση:
hardlim(n) = 1, αν n ≥ 0
hardlim(n) = 0, αν n < 0
Με άλλα λόγια, αν το συνολικό σήμα του νευρώνα είναι θετικό, η έξοδος είναι 1, αλλιώς 0.
Έτσι το perceptron λειτουργεί σαν ένας απλός μηχανισμός απόφασης που χωρίζει τα δεδομένα
σε δύο κατηγορίες.
Ο πίνακας αληθείας της πράξης AND:
| x1 | x2 | Έξοδος |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
import numpy as np
# Δεδομένα εκπαίδευσης (AND)
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 0, 0, 1])
# Αρχικοποίηση
weights = np.random.rand(2)
bias = np.random.rand()
def activation(x):
return 1 if x >= 0 else 0
learning_rate = 0.1
# Εκπαίδευση
for epoch in range(10):
for i in range(len(X)):
n = np.dot(X[i], weights) + bias
y_pred = activation(n)
error = y[i] - y_pred
weights += learning_rate * error * X[i]
bias += learning_rate * error
# Δοκιμή
print("Αποτελέσματα:")
for x in X:
output = activation(np.dot(x, weights) + bias)
print(x, "->", output)
Παράδειγμα ενός Iteration (μέσα από τον κώδικα)
Ας δούμε τι κάνει ο κώδικας για ένα δείγμα εκπαίδευσης: Έστω: X[i] = [1, 0] y[i] = 0 και αρχικά: weights = [0.4, 0.6] bias = 0.2 learning_rate = 0.1 Τα weights και το bias:
Ξεκινούν με τυχαίες τιμές (random initialization), όπως φαίνεται και στον κώδικα:
weights = np.random.rand(2)
bias = np.random.rand()
Στη συνέχεια, το ίδιο το μοντέλο τα προσαρμόζει κατά την εκπαίδευση. ---------------------------------- Βήμα 1: Υπολογισμός του n n = np.dot(X[i], weights) + bias = (1*0.4 + 0*0.6) + 0.2 = 0.6 ---------------------------------- Βήμα 2: Activation function y_pred = activation(n) = 1 (γιατί 0.6 ≥ 0) ---------------------------------- Βήμα 3: Υπολογισμός σφάλματος error = y[i] - y_pred = 0 - 1 = -1 ---------------------------------- Βήμα 4: Ενημέρωση βαρών weights += learning_rate * error * X[i] weights[0] = 0.4 + 0.1 * (-1) * 1 = 0.3 weights[1] = 0.6 + 0.1 * (-1) * 0 = 0.6 ---------------------------------- Βήμα 5: Ενημέρωση bias bias += learning_rate * error bias = 0.2 + 0.1 * (-1) = 0.1 ---------------------------------- Νέα τιμές: weights = [0.3, 0.6] bias = 0.1
Βιβλιογραφία
Hagan, M. T., Demuth, H. B., Beale, M. H., & De Jesús, O. (2014). Neural network design (2nd ed.).